Belleği kullanma şeklimizin performans üzerinde büyük bir etkisi olabileceği artık sürpriz olmamalıdır. CPU, CPU register’ları ve ana bellek arasında veri karıştırmak için çok zaman harcar (ana belleğe ve ana bellekten veri yüklemek ve depolamak). CPU belleğe erişimi hızlandırmak için hafıza önbelleklerini kullanır ve programların hızlı çalışması için önbellek dostu olması gerekir.
Bu bölüm, bilgisayarların bellekle nasıl çalıştığına dair daha fazla yönü ortaya çıkaracak, böylece bellek kullanımını ayarlarken nelere dikkat etmeniz gerektiğini bileceksiniz. Ayrıca bu bölüm şunları da kapsamaktadır:
- Otomatik bellek tahsisi ve dinamik bellek yönetimi.
- Bir C++ nesnesinin yaşam döngüsü ve nesne sahipliğinin nasıl yönetileceği.
- Verimli bellek yönetimi. Bazen bizi veri gösterimimizi kompakt tutmaya zorlayan katı bellek sınırları vardır ve bazen de bol miktarda belleğimiz vardır ancak bellek yönetimini daha verimli hale getirerek programın daha hızlı ilerlemesine ihtiyaç duyarız.
-
Dinamik bellek tahsisleri nasıl en aza indirilir. Dinamik bellek ayırmak ve ayırma işlemini kaldırmak nispeten zahmetlidir ve zaman zaman programın daha hızlı çalışmasını sağlamak için gereksiz ayırma işlemlerinden kaçınmamız gerekir.
Bu bölüme, C++ bellek yönetimini derinlemesine incelemeden önce anlamanız gereken bazı kavramları açıklayarak başlayacağız. Bu giriş bölümünde sanal bellek ve sanal adres alanları, stack belleğe karşı heap bellek, paging ve swap space açıklanacaktır.
Computer Memory
Bir bilgisayarın fiziksel belleği, sistemde çalışan tüm işlemler arasında paylaşılır. Eğer bir süreç çok fazla bellek kullanırsa, diğer süreçler de büyük olasılıkla bundan etkilenecektir. Ancak bir programcının bakış açısından, genellikle diğer süreçler tarafından kullanılan bellek hakkında endişelenmemiz gerekmez. Bu bellek izolasyonu, günümüzde çoğu işletim sisteminin, bir sürecin tüm belleğe sahip olduğu yanılsamasını sağlayan sanal bellek işletim sistemleri olmasından kaynaklanmaktadır. Her sürecin kendi sanal adres alanı vardır.
The Virtual Address Space
Programcıların gördüğü sanal adres alanındaki adresler, işletim sistemi ve işlemcinin bir parçası olan bellek yönetim birimi (MMU) tarafından fiziksel adreslerle eşleştirilir. Bu eşleme veya çeviri, bir bellek adresine her eriştiğimizde gerçekleşir.
Bu ekstra dolaylı katman, işletim sisteminin bir sürecin o anda kullanılmakta olan kısımları için fiziksel belleği kullanmasını ve sanal belleğin geri kalanını diskte yedeklemesini mümkün kılar. Bu anlamda fiziksel ana belleğe, ikincil depolama alanında bulunan sanal bellek alanı için bir önbellek olarak bakabiliriz. Bellek sayfalarını yedeklemek için kullanılan ikincil depolama alanları, işletim sistemine bağlı olarak genellikle swap space (takas alanı), swap file (takas dosyası) ya da sadece pagefile (sayfa dosyası) olarak adlandırılır.
Sanal bellek, işlemlerin fiziksel adres alanından daha büyük bir sanal adres alanına sahip olmasını mümkün kılar, çünkü kullanılmayan sanal belleğin fiziksel belleği işgal etmesi gerekmez.
Memory Pages
Günümüzde sanal belleği uygulamanın en yaygın yolu, adres alanını bellek sayfaları adı verilen sabit boyutlu bloklara bölmektir. Bir işlem sanal bir adresteki belleğe eriştiğinde, işletim sistemi bellek sayfasının fiziksel bellek (bir sayfa çerçevesi) tarafından desteklenip desteklenmediğini kontrol eder. Bellek sayfası ana bellekte eşlenmemişse, bir donanım istisnası meydana gelir ve sayfa diskten belleğe yüklenir. Bu tür donanım istisnasına sayfa hatası denir. Bu bir hata değil, diskten belleğe veri yüklemek için gerekli bir kesmedir. Tahmin edebileceğiniz gibi, bu işlem bellekte zaten yerleşik olan verileri okumaya kıyasla çok yavaştır.
Ana bellekte daha fazla kullanılabilir sayfa çerçevesi kalmadığında, bir sayfa çerçevesinin tahliye edilmesi gerekir. Tahliye edilecek sayfa kirliyse, yani diskten en son yüklendiğinden beri değiştirilmişse, değiştirilmeden önce diske yazılması gerekir.Bu mekanizmaya paging(sayfalama) adı verilir. Bellek sayfası değiştirilmemişse, bellek sayfası basitçe boşaltılır.
Sanal belleği destekleyen tüm işletim sistemleri sayfalamayı desteklemez. iOS, örneğin, sanal belleğe sahiptir ancak kirli sayfalar asla diskte saklanmaz; yalnızca temiz sayfalar bellekten çıkarılabilir. Eğer ana bellek dolmuşsa, iOS tekrar yeterli boş bellek olana kadar işlemleri sonlandırmaya başlayacaktır. Android de benzer bir strateji kullanır. Bellek sayfalarının mobil cihazların flash depolama alanına geri yazılmamasının bir nedeni de bunun pili tüketmesi ve flash depolama alanının ömrünü kısaltmasıdır.
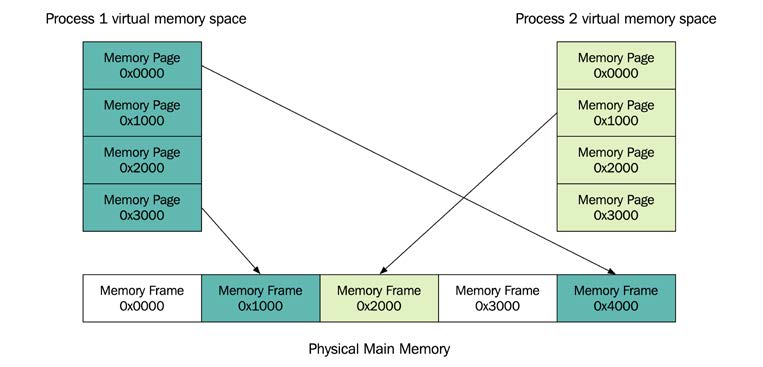
Aşağıdaki diyagramda çalışan iki süreç gösterilmektedir. Her ikisinin de kendi sanal bellek(virtual memory) alanı vardır. Bazı sayfalar fiziksel bellekle eşlenirken bazıları eşlenmez. Eğer süreç(process) 1’in 0x1000 adresinden başlayan bellek sayfasındaki belleği kullanması gerekirse, bir sayfa hatası oluşacaktır. Bellek sayfası daha sonra boş bir bellek çerçevesine eşlenecektir. Ayrıca, sanal bellek adreslerinin fiziksel adreslerle aynı olmadığına dikkat edin. İşlem 1’in 0x0000 sanal adresinden başlayan ilk bellek sayfası, 0x4000 fiziksel adresinden başlayan bir bellek çerçevesine eşlenir:
Thrashing
Thrashing, bir sistemin fiziksel belleği azaldığında ve bu nedenle sürekli olarak sayfalama yaptığında meydana gelebilir. Ne zaman bir işlem CPU üzerinde zamanlansa, sayfalanmış belleğe erişmeye çalışır. Yeni bellek sayfalarının yüklenmesi, diğer sayfaların önce diskte depolanması gerektiği anlamına gelir. Verilerin disk ve bellek arasında ileri geri taşınması genellikle çok yavaştır; bazı durumlarda, sistem tüm zamanını sayfalamaya harcadığından bu durum bilgisayarı yavaşlatır. Sistemin sayfa hatası frekansına bakmak, programın çökmeye başlayıp başlamadığını belirlemenin iyi bir yoludur. Belleğin donanım ve işletim sistemi tarafından nasıl işlendiğine dair temel bilgileri bilmek, performansı optimize ederken önemlidir.Daha sonra, bir C++ programının yürütülmesi sırasında belleğin nasıl işlendiğini göreceğiz.
Öncelikle durumu daha iyi kavrayabilmek adına hafıza yönetimi konusunda biraz bilgiye sahip olmamız gerekmektedir. Öncelikle Stack ve Heap hakkında kısa bilgi aktaracağım.
Process Memory
Stack ve heap bir C++ programındaki en önemli iki bellek bölümüdür. Ayrıca statik depolama ve iş parçacığı yerel depolaması da vardır, ancak bu konuda daha sonra daha fazla konuşacağız. Aslında, resmi olarak doğru olmak gerekirse, C++ stack ve heap’ten bahsetmez; bunun yerine, serbest depodan, depolama sınıflarından ve nesnelerin depolama süresinden bahseder. Ancak, stack ve heap kavramları C++ topluluğunda yaygın olarak kullanıldığından ve bildiğimiz tüm C++ uygulamaları işlev çağrılarını uygulamak ve yerel değişkenlerin otomatik depolanmasını yönetmek için bir stack kullandığından, stack ve heap’in ne olduğunu anlamak önemlidir.
Bu yazımızda nesnelerin depolama süresi yerine stack ve heap terimlerini kullanacağım. Heap ve free store terimlerini birbirlerinin yerine kullanacağım ve aralarında herhangi bir ayrım yapmayacağım.
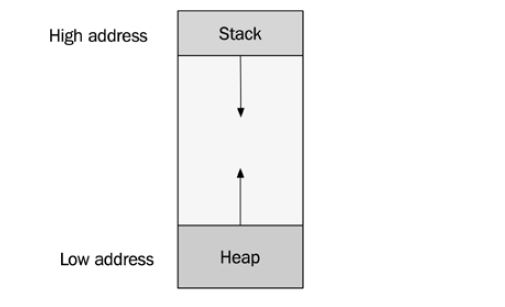
Hem stack hem de heap sürecin sanal bellek alanında bulunur. Stack tüm yerel değişkenlerin bulunduğu bir yerdir; buna fonksiyonların argümanları da dahildir. Stack, bir fonksiyon her çağrıldığında büyür ve bir fonksiyon geri döndüğünde küçülür. Her iş parçacığının kendi stack’i vardır ve bu nedenle stack belleği iş parçacığı güvenli olarak kabul edilebilir. Öte yandan heap, tüm iş parçacıkları arasında paylaşılan küresel bir bellek alanıdır. Heap new (veya C kütüphanesi fonksiyonları malloc() ve calloc()) ile bellek ayırdığımızda büyür ve belleği delete (veya free()) ile boşalttığımızda küçülür. Genellikle heap düşük bir adresten başlar ve yukarı doğru büyürken, stack yüksek bir adresten başlar ve aşağı doğru büyür. Aşağıdaki şekilde sanal bir adres alanında stack ve heap’in nasıl zıt yönlerde büyüdüğünü göstermektedir:
Stack Memory
Stack, heape kıyasla birçok yönden farklılık gösterir. İşte stack’in benzersiz özelliklerinden bazıları:
- Stack, bitişik bir bellek bloğudur.
- Sabit bir maksimum boyutu vardır. Bir program maksimum stack boyutunu aşarsa, program çökecektir. Bu duruma yığın taşması(stack overflow-buffer overflow) denir.
- Stack belleği asla parçalanmaz.
- Stack den bellek ayırmak (neredeyse) her zaman hızlıdır. Sayfa hataları mümkündür ancak nadirdir.
- Bir programdaki her iş parçacığının kendi stack i vardır.
Bu bölümün devamındaki kod örnekleri bu özelliklerden bazılarını inceleyecektir. Stack’in bir programda nasıl kullanıldığına dair bir fikir edinmek için allocation ve deallocation ile başlayalım.
Stack’e ayrılan verinin adresini inceleyerek stack’in hangi yönde büyüdüğünü kolayca bulabiliriz. Aşağıdaki örnek kod, fonksiyonlara girerken ve fonksiyonlardan çıkarken yığının nasıl büyüdüğünü ve küçüldüğünü göstermektedir:
void func1()
{
auto i = 0;
std::cout << "func1(): " << std::addressof(i) << '\n';
}
void func2()
{
auto i = 0;
std::cout << "func2(): " << std::addressof(i) << '\n';
func1();
}
int main()
{
auto i = 0;
std::cout << "main(): " << std::addressof(i) << '\n';
func2();
func1();
}
main(): 0x7ea075ac
func2(): 0x7ea07594
func1(): 0x7ea0757c
func1(): 0x7ea07594
Stack için ayrılan tamsayının adresini yazdırarak, platformumda stack’in ne kadar ve hangi yönde büyüdüğünü belirleyebiliriz. Her func1() ya da func2() girdiğimizde stack 24 byte büyüyor. Stack üzerinde tahsis edilecek olan i tamsayısı 4 byte uzunluğundadır. Kalan 20 bayt, fonksiyon sona erdiğinde ihtiyaç duyulan verileri, örneğin dönüş adresini ve belki de hizalama için bir miktar dolguyu içerir.Aşağıdaki diyagram, programın yürütülmesi sırasında stack’in nasıl büyüdüğünü ve daraldığını göstermektedir. İlk kutu, program main() işlevine yeni girdiğinde belleğin nasıl göründüğünü göstermektedir. İkinci kutu, func1() fonksiyonunu çalıştırdığımızda stack’in nasıl arttığını gösterir ve bu böyle devam eder:
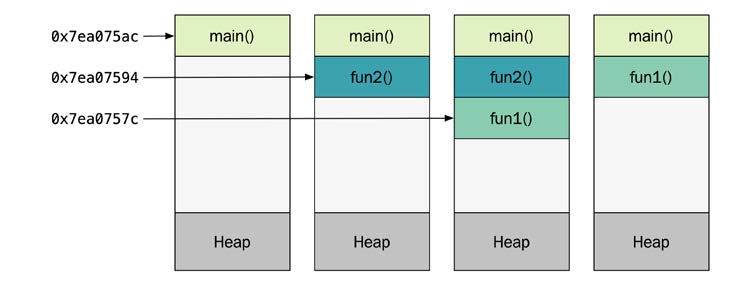
Stack için ayrılan toplam bellek, iş parçacığı başlangıcında oluşturulan sabit boyutlu bir bitişik bellek bloğudur. Peki, stack ne kadar büyüktür ve stack’in sınırına ulaştığımızda ne olur?
Daha önce de belirtildiği gibi, program bir işleve her girdiğinde stack büyür ve fonksiyon geri döndüğünde daralır. Stack ayrıca aynı fonksiyon içinde yeni bir stack değişkeni yarattığımızda büyür ve böyle bir değişken kapsam dışına çıktığında daralır. Stack’in taşmasının en yaygın nedeni derin özyinelemeli çağrılar ve/veya stack üzerinde büyük, kendiliğinden değişkenler kullanmaktır. Stack’in maksimum boyutu platformlar arasında farklılık gösterir ve ayrıca bireysel süreçler ve iş parçacıkları için de yapılandırılabilir.
Bakalım sistemimde varsayılan olarak stack’in ne kadar büyük olduğunu görmek için bir program yazabilecek miyiz? Sonsuza kadar tekrar eden bir fonksiyon, func(), yazarak başlayacağız. Her fonksiyonun başında, 1 kilobaytlık bir değişken tahsis edeceğiz ve bu değişken func() işlevine her girdiğimizde stack üzerine yerleştirilir. func() her çalıştırıldığında, bize yığının geçerli boyutunu yazdırır:
void func(std::byte* stack_bottom_addr)
{
std::byte data[1024];
std::cout << stack_bottom_addr - data << '\n';
func(stack_bottom_addr);
}
int main()
{
std::byte b;
func(&b);
}
Stack’in boyutu sadece bir tahmindir. Bunu main() içindeki ilk yerel değişkenin adresini func() içinde tanımlanan ilk yerel değişkenden çıkararak hesaplıyoruz.
Kodu Clang ile derlediğimde, func()’un asla geri dönmeyeceğine dair bir uyarı aldım. Normalde, bu göz ardı etmememiz gereken bir uyarıdır, ancak bu sefer, bu tam olarak istediğimiz sonuç, bu yüzden uyarıyı görmezden geliyoruz ve programı yine de çalıştırıyoruz. Program kısa bir süre sonra stack sınırına ulaştığında çöküyor. Program çökmeden önce, yığının mevcut boyutuyla birlikte binlerce satır çıktı almayı başarıyor. Çıktının son satırları şu şekilde görünür:
...
8378667
8379755
8380843
std::byte işaretçilerini çıkardığımız için, boyut bayt cinsindendir, bu nedenle stack’in maksimum boyutu benim sistemimde 8 MB civarında görünüyor. Unix benzeri sistemlerde, ulimit komutunu kullanarak süreçler için yığın boyutunu ayarlamak ve almak mümkündür -s seçeneği ile:
$ ulimit -s
$ 8192
ulimit (kullanıcı sınırının kısaltması) maksimum stack boyutu için geçerli ayarı kilobayt cinsinden döndürür.
ulimit’in çıktısı deneyimizden elde ettiğimiz sonuçları doğruluyor:Mac’imde açıkça yapılandırmadığım takdirde stack boyutu yaklaşık 8 MB.
Windows’ta varsayılan stack boyutu genellikle 1 MB olarak ayarlanmıştır. MacOS’ta sorunsuz çalışan bir program, stack boyutu doğru yapılandırılmamışsa Windows’ta stack taşması nedeniyle çökebilir.
Bu örnekle, stack belleğinin tükenmesini istemediğimiz sonucuna da varabiliriz, çünkü bu gerçekleştiğinde program çökecektir. Bu bölümün ilerleyen kısımlarında, sabit boyutlu ayırmaları işlemek için ilkel bir bellek ayırıcıyı nasıl uygulayacağımızı göreceğiz. Daha sonra stack’in, kullanım şekli her zaman sıralı olduğu için çok verimli bir şekilde uygulanabilen başka bir bellek ayırıcı türü olduğunu anlayacağız. Belleği her zaman stack’in tepesinden (bitişik belleğin sonu) talep eder ve serbest bırakırız. Bu, stack belleğinin asla parçalanmamasını ve sadece bir stack işaretçisini hareket ettirerek bellek tahsis edebilmemizi ve ayırabilmemizi sağlar.
Heap Memory
Heap (ya da C++’da daha doğru bir terim olan serbest depo) dinamik depolamaya sahip verilerin bulunduğu yerdir. Daha önce de belirtildiği gibi, heap birden fazla iş parçacığı arasında paylaşılır, bu da heap için bellek yönetiminin eşzamanlılığı dikkate alması gerektiği anlamına gelir. Bu, heap’teki bellek tahsislerini iş parçacığı başına yerel olan stack tahsislerinden daha karmaşık hale getirir.
Stack bellek için tahsis ve tahsis dışı bırakma modeli sıralıdır, yani bellek her zaman tahsis edildiği sıranın tersi sırada tahsis dışı bırakılır. Öte yandan, dinamik bellek için tahsis(allocation) ve tahsis dışı bırakma(deallocation) keyfi olarak gerçekleşebilir. Nesnelerin dinamik yaşam süreleri ve bellek tahsislerinin değişken boyutları, belleğin parçalanma riskini artırır.
Bellek parçalanması ile ilgili sorunu anlamanın kolay bir yolu, parçalanmış belleğin nasıl oluşabileceğine dair bir örnek üzerinden gitmektir. Bellek ayırdığımız 16 KB’lık küçük bir bitişik bellek bloğumuz olduğunu varsayalım. İki türde nesne tahsis ediyoruz: 1 KB olan A tipi ve 2 KB olan B tipi. Önce A türünde bir nesne, ardından da B türünde bir nesne tahsis ediyoruz. Bu işlem, bellek aşağıdaki görüntüye benzeyene kadar tekrarlanır:

Daha sonra, A türündeki tüm nesnelere artık ihtiyaç duyulmadığından bunlar bellekten çıkarılabilir. Bellek şimdi şöyle görünür:

Şu anda 10 KB bellek kullanılıyor ve 6 KB kullanılabilir durumda. Şimdi, 2 KB’lık B tipi yeni bir nesne tahsis etmek istediğimizi varsayalım. Her ne kadar 6 KB boş bellek olsa da, bellek parçalandığı için 2 KB’lık bir bellek bloğu bulabileceğimiz hiçbir yer yok.
Artık bilgisayar belleğinin nasıl yapılandırıldığını ve çalışan bir süreçte nasıl kullanıldığını iyi bir şekilde anladığınıza göre, C++ nesnelerinin bellekte nasıl yaşadığını keşfetmenin zamanı geldi.
Objects in Memory
Bir C++ programında kullandığımız tüm nesneler bellekte bulunur. Burada, nesnelerin bellekte nasıl oluşturulduğunu ve bellekten nasıl silindiğini inceleyeceğiz ve ayrıca nesnelerin bellekte nasıl düzenlendiğini açıklayacağız.
Creating and Deleting Objects
Bu bölümde, new ve delete kullanımının ayrıntılarını inceleyeceğiz. Serbest depoda bir nesne oluşturmak için new kullanmanın ve ardından delete kullanarak silmenin aşağıdaki yolunu düşünün:
auto* user = new User{"John"}; // allocate and construct
user->print_name(); // use object
delete user; // destruct and deallocate
Bu şekilde new ve delete’i açıkça çağırmanızı önermiyorum, ancak şimdilik bunu görmezden gelelim. Sadede gelelim; yorumlardan da anlaşılacağı gibi, new aslında iki şey yapar:
- User türünde yeni bir nesneyi tutmak için bellek ayırır
- User sınıfının kurucusunu(constructor) çağırarak tahsis edilen bellek alanında yeni bir User nesnesi oluşturur
Aynı şey delete için de geçerlidir:
- Yıkıcısını(destructor) çağırarak User nesnesini yok eder
- User nesnesinin yerleştirildiği belleği ayırır/boşaltır
Aslında C++’da bu iki eylemi (bellek ayırma ve nesne oluşturma=memory allocation and object construction) birbirinden ayırmak mümkündür. Bu nadiren kullanılır ancak kütüphane bileşenleri yazarken bazı önemli ve meşru kullanım durumları vardır.
Placement New
C++, bellek tahsisini object construction’dan ayırmamıza izin verir. Örneğin, malloc() ile bir bayt dizisi tahsis edebilir ve bu bellek bölgesinde yeni bir User nesnesi oluşturabiliriz. Aşağıdaki kod parçasına bir göz atın:
auto* memory = std::malloc(sizeof(User));
auto* user = ::new (memory) User("john");
Bu kullandığımız ve pek aşina olmadığımız ::new ( memory) söz dizimine placement new denir. Yalnızca bir nesne oluşturan new’in ayırma yapmayan bir biçimidir. new’in önündeki çift iki nokta (::), new operatörünün aşırı yüklenmiş bir versiyonunu kullanmaktan kaçınmak için çözümlemenin global isim alanından yapılmasını sağlar.
Yukarıdaki örnekte, new yerleştirmesi User nesnesini oluşturur ve onu belirtilen bellek konumuna yerleştirir. Belleği std::malloc() ile tek bir nesne için ayırdığımızdan, doğru hizalanmış olması garanti edilir (User sınıfı aşırı hizalanmış olarak bildirilmediği sürece). Daha sonra, placement new kullanırken hizalamayı dikkate almamız gereken durumları inceleyeceğiz.
Placement’da delete yoktur, bu nedenle nesneyi yok etmek ve belleği boşaltmak için destructor’ı açıkça çağırmamız ve ardından belleği boşaltmamız gerekir:
user->~User();
std::free(memory);
C++17, bellek ayırmadan veya bellekten çıkarmadan nesneleri oluşturmak ve yok etmek için <memory> içinde bir dizi yardımcı işlev sunar. Bu nedenle, placement new’i çağırmak yerine, artık <memory>’deki adları std::uninitialized_ ile başlayan bazı işlevleri nesneleri oluşturmak, kopyalamak ve başlatılmamış bir bellek alanına taşımak için kullanmak mümkündür. Ve destructor’ı açıkça çağırmak yerine, artık belleği ayırmadan belirli bir bellek adresindeki bir nesneyi yok etmek için std::destroy_at() kullanabiliriz.
Önceki örnek bu yeni fonksiyonlar kullanılarak yeniden yazılabilir. İşte nasıl görüneceği:
auto* memory = std::malloc(sizeof(User));
auto* user_ptr = reinterpret_cast<User*>(memory);
std::uninitialized_fill_n(user_ptr, 1, User{"john"});
std::destroy_at(user_ptr);
std::free(memory);
C++20 ayrıca, std::uninitialized_fill_n() çağrısını std::construct_at() ile değiştirmeyi mümkün kılar:
std::construct_at(user_ptr, User{"john"}); // C++20
Lütfen C++’da bellek yönetimini daha iyi anlamak için bu temel düşük seviye bellek olanaklarını gösterdiğimizi unutmayın. Burada gösterilen reinterpret_cast ve bellek yardımcı programlarının kullanımı bir C++ kod tabanında mutlak minimumda tutulmalıdır.
Daha sonra, new ve delete ifadelerini kullandığımızda hangi operatörlerin çağrıldığını göreceksiniz.
The new and delete operators
new işlev operatörü, new ifadesi çağrıldığında bellek ayırmaktan sorumludur. new işleci, global olarak tanımlanmış bir işlev ya da bir sınıfın statik üye işlevi olabilir. new ve delete global operatörlerini aşırı yüklemek mümkündür. Bu bölümün ilerleyen kısımlarında, bunun bellek kullanımını analiz ederken faydalı olabileceğini göreceğiz.
İşte nasıl yapılacağı:
auto operator new(size_t size) -> void* {
void* p = std::malloc(size);
std::cout << "allocated " << size << " byte(s)\n";
return p;
}
auto operator delete(void* p) noexcept -> void {
std::cout << "deleted memory\n";
return std::free(p);
}
Bir char nesnesi oluştururken ve silerken aşırı yüklenmiş operatörlerimizin gerçekten kullanıldığını doğrulayabiliriz:
auto* p = new char{'a'}; // Outputs "allocated 1 byte(s)"
delete p; // Outputs "deleted memory"
new[] ve delete[] ifadelerini kullanarak bir nesne dizisi oluştururken ve silerken, kullanılan başka bir operatör çifti daha vardır, bunlar operator new[] ve operator delete[]’dir. Bu operatörleri de aynı şekilde aşırı yükleyebiliriz:
auto operator new[](size_t size) -> void* {
void* p = std::malloc(size);
std::cout << "allocated " << size << " byte(s) with new[]\n";
return p;
}
auto operator delete[](void* p) noexcept -> void {
std::cout << "deleted memory with delete[]\n";
return std::free(p);
}
Eğer operator new’i aşırı yüklerseniz, operator delete’i de aşırı yüklemeniz gerektiğini unutmayın. Bellek ayırma ve bellekten çıkarma işlevleri çiftler halinde gelir. Bellek, belleğin tahsis edildiği allocator tarafından deallocate edilmelidir. Örneğin, std::malloc() ile tahsis edilen bellek her zaman std::free() kullanılarak serbest bırakılmalı, new[] operatörü ile tahsis edilen bellek ise delete[] operatörü kullanılarak serbest bırakılmalıdır.
Sınıfa özgü bir operator new veya operator delete’i geçersiz kılmak da mümkündür. Bu muhtemelen global operatörleri aşırı yüklemekten daha kullanışlıdır, çünkü belirli bir sınıf için özel bir dinamik bellek ayırıcıya ihtiyaç duyma olasılığımız daha yüksektir.
Burada, Document sınıfı için new ve delete operatörlerini aşırı yüklüyoruz:
class Document
{
// ...
public:
auto operator new(size_t size) -> void* {
return ::operator new(size);
}
auto operator delete(void* p) -> void {
::operator delete(p);
}
};
Dinamik olarak ayrılmış yeni Document nesneleri oluşturduğumuzda new’in sınıfa özgü sürümü kullanılacaktır:
auto* p = new Document{}; // Uses class-specific operator new
delete p;
Bunun yerine global new ve delete kullanmak istersek, global kapsamı (::) kullanarak bunu yapmak hala mümkündür:
auto* p = ::new Document{}; // Uses global operator new
::delete p;
Bu bölümün ilerleyen kısımlarında bellek ayırıcıları(memory allocators) tartışacağız ve daha sonra aşırı yüklenmiş new ve delete operatörlerinin kullanımını göreceğiz.
Şimdiye kadar gördüklerimizi özetlemek gerekirse, bir new ifadesi iki şey içerir: allocation ve construction. new operatörü bellek tahsis eder ve dinamik bellek yönetimini özelleştirmek için global olarak veya sınıf bazında aşırı yükleyebilirsiniz. Placement new, önceden tahsis edilmiş bir bellek alanında bir nesne oluşturmak için kullanılabilir.
>Belleği verimli bir şekilde kullanmak için anlamamız gereken bir diğer önemli, ancak oldukça düşük seviyeli konu da belleğin hizalanmasıdır.
Memory Alignment
CPU, belleği her seferinde bir word olmak üzere register’ları okur. Kelime boyutu 64 bitlik bir mimaride 64 bit, 32 bitlik bir mimaride 32 bit ve benzeridir. CPU’nun farklı veri türleriyle çalışırken verimli çalışabilmesi için, farklı türlerdeki nesnelerin bulunduğu adresler üzerinde kısıtlamaları vardır. C++’daki her tür, belirli bir türdeki bir nesnenin bellekte bulunması gereken adresleri tanımlayan bir hizalama gereksinimine sahiptir.
Bir türün hizalaması 1 ise, bu, o türün nesnelerinin herhangi bir bayt adresinde bulunabileceği anlamına gelir. Bir türün hizalaması 2 ise, bu, ardışık izin verilen adresler arasındaki bayt sayısının 2 olduğu anlamına gelir. Ya da C++ standardından alıntı yapmak gerekirse:
Hizalama(alignment), belirli bir nesnenin tahsis edilebileceği ardışık adresler arasındaki bayt sayısını temsil eden uygulama tanımlı bir integer değerdir.
Bir türün hizalamasını bulmak için alignof’u kullanabiliriz:
// Possible output is 4
std::cout << alignof(int) << '\n';
Bu kodu çalıştırdığımda 4 çıktısı veriyor, bu da int türünün hizalama gereksiniminin benim platformumda 4 bayt olduğu anlamına geliyor.
Aşağıdaki şekilde 64 bitlik sözcüklere sahip bir sistemden iki bellek örneği gösterilmektedir. Üst satır, 4 bayt hizalanmış adreslerde bulunan üç adet 4 baytlık tamsayı içerir. CPU bu tamsayıları verimli bir şekilde registerlara yükleyebilir ve int üyelerinden birine erişirken asla birden fazla kelime okumak zorunda kalmaz. Bunu, hizalanmamış adreslerde bulunan iki int üyesi içeren ikinci satırla karşılaştırın. Hatta ikinci int iki kelime sınırı boyunca uzanır. En iyi durumda, bu sadece verimsizdir, ancak bazı platformlarda program çökecektir:
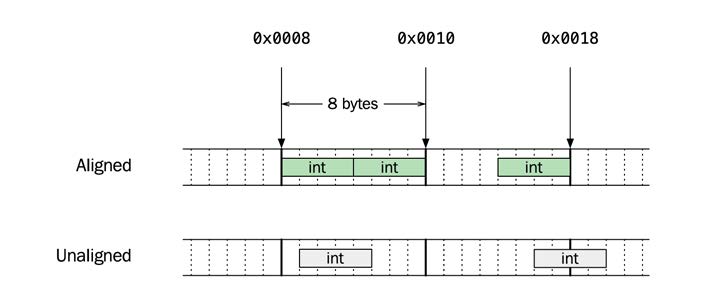
Diyelim ki hizalama gereksinimi 2 olan bir tipimiz var. C++ standardı geçerli adreslerin 1, 3, 5, 7… mi yoksa 0, 2, 4, 6 mı olduğunu söylemiyor….
Bildiğimiz tüm platformlar adresleri saymaya 0’dan başlar, bu nedenle pratikte bir nesnenin doğru hizalanıp hizalanmadığını, adresinin modulo operatörünü (%) kullanarak hizalamanın bir katı olup olmadığını kontrol ederek kontrol edebiliriz.
Ancak, tamamen taşınabilir C++ kodu yazmak istiyorsak, bir nesnenin hizalamasını kontrol etmek için modulo değil std::align() kullanmamız gerekir. std::align(), <memory>’den bir işlevdir ve bir işaretçiyi argüman olarak ilettiğimiz bir hizalamaya göre ayarlar. Eğer ona ilettiğimiz bellek adresi zaten hizalanmışsa, işaretçi ayarlanmayacaktır. Bu nedenle, std::align() fonksiyonunu aşağıdaki gibi is_aligned() adlı küçük bir yardımcı fonksiyon olarak kullanabiliriz:
bool is_aligned(void* ptr, std::size_t alignment) {
assert(ptr != nullptr);
assert(std::has_single_bit(alignment)); // Power of 2
auto s = std::numeric_limits<std::size_t>::max();
auto aligned_ptr = ptr;
std::align(alignment, 1, aligned_ptr, s);
return ptr == aligned_ptr;
}
İlk olarak, ptr argümanının null olmadığından ve hizalamanın C++ standardında bir gereklilik olarak belirtilen 2’nin kuvveti olduğundan emin oluyoruz. Bunu kontrol etmek için <bit> başlığından C++20 std::has_single_bit() kullanıyoruz. Ardından, std::align() işlevini çağırıyoruz. std::align() için tipik kullanım durumu, bazı hizalama gereksinimleri olan bir nesneyi saklamak istediğimiz belirli bir boyutta bir bellek tamponumuz olduğunda ortaya çıkar. Bu durumda, bir tamponumuz yok ve nesnelerin boyutunu önemsemiyoruz, bu yüzden nesnenin 1 boyutunda olduğunu ve tamponun bir std::size_t’nin maksimum değeri olduğunu söylüyoruz. Daha sonra, orijinal ptr ile düzeltilmiş aligned_ptr’yi karşılaştırarak orijinal işaretçinin zaten hizalanmış olup olmadığını görebiliriz. Bu yardımcı programı ilerideki örneklerde kullanacağız.
new veya std::malloc() ile bellek ayırırken, geri aldığımız bellek belirttiğimiz tür için doğru şekilde hizalanmış olmalıdır. Aşağıdaki kod int için ayrılan belleğin benim platformumda en az 4 bayt hizalı olduğunu gösteriyor:
auto* p = new int{};
assert(is_aligned(p, 4ul)); // True
Aslında, new ve malloc() işlevlerinin her zaman herhangi bir skaler tip için uygun şekilde hizalanmış bellek döndürmesi garanti edilir (eğer bellek döndürmeyi başarırsa). <cstddef> başlığı bize std::max_align_t adında, hizalama gereksinimi en az tüm skaler tipler kadar katı olan bir tip sağlar. Daha sonra, bu türün özel bellek ayırıcılar yazarken yararlı olduğunu göreceğiz. Böylece, serbest depoda sadece char için bellek talep etsek bile, std::max_align_t için uygun şekilde hizalanacaktır.
Aşağıdaki kod, new’den dönen belleğin std::max_align_t ve ayrıca herhangi bir skaler tip için doğru şekilde hizalandığını gösterir:
auto* p = new char{};
auto max_alignment = alignof(std::max_align_t);
assert(is_aligned(p, max_alignment)); // True
char’ı new ile arka arkaya iki kez tahsis edelim:
auto* p1 = new char{'a'};
auto* p2 = new char{'b'};
O zaman, bellek şöyle bir şeye benzeyebilir:
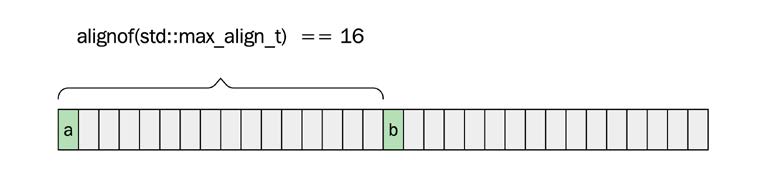
p1 ve p2 arasındaki boşluk std::max_ align_t’nin hizalama gereksinimlerine bağlıdır. Benim sistemimde bu 16 bayttı ve bu nedenle, bir char’ın hizalaması yalnızca 1 olmasına rağmen, her char örneği arasında 15 bayt vardır.
alignas belirticisini kullanarak bir değişken bildirirken varsayılan hizalamadan daha katı olan özel hizalama gereksinimlerini belirtmek mümkündür. Diyelim ki 64 baytlık bir önbellek satır boyutumuz var ve herhangi bir nedenle iki değişkenin ayrı önbellek satırlarına yerleştirilmesini sağlamak istiyoruz. Aşağıdakileri yapabiliriz:
alignas(64) int x{};
alignas(64) int y{};
// x and y will be placed on different cache lines
Bir türü tanımlarken özel bir hizalama belirtmek de mümkündür. Aşağıda, kullanıldığında tam olarak bir önbellek satırı kaplayacak bir struct verilmiştir:
struct alignas(64) CacheLine {
std::byte data[64];
};
Şimdi, CacheLine türünde bir yığın değişkeni oluşturacak olsaydık, 64 baytlık özel hizalamaya göre hizalanırdı:
int main() {
auto x = CacheLine{};
auto y = CacheLine{};
assert(is_aligned(&x, 64));
assert(is_aligned(&y, 64));
// ...
}
Daha katı hizalama gereksinimleri, yığın üzerinde nesneler tahsis edilirken de karşılanır. Varsayılan olmayan hizalama gereksinimleri olan türlerin dinamik tahsisini desteklemek için, C++17, std::align_val_t türünde bir hizalama argümanı kabul eden operator new() ve operator delete() için yeni aşırı yüklemeler getirmiştir. Ayrıca <cstdlib> içinde tanımlanmış bir aligned_alloc() fonksiyonu vardır ve bu fonksiyon hizalanmış heap belleğini manuel olarak tahsis etmek için kullanılabilir.
Aşağıda, tam olarak bir bellek sayfası kaplaması gereken bir yığın bellek bloğu ayırdığımız bir örnek yer almaktadır. Bu durumda, new ve delete kullanılırken operator new() ve operator delete() işlevlerinin hizalamaya duyarlı sürümleri çağrılacaktır:
constexpr auto ps = std::size_t{4096}; // Page size
struct alignas(ps) Page {
std::byte data_[ps];
};
auto* page = new Page{}; // Memory page
assert(is_aligned(page, ps)); // True
// Use page ...
delete page;
Bellek sayfaları C++ soyut(abstract) mekanizmasının bir parçası değildir, bu nedenle o anda çalışan sistemin sayfa boyutunu programlı olarak elde etmenin taşınabilir bir yolu yoktur. Bununla birlikte, boost::mapped_region::get_page_size() veya Unix sistemlerinde getpagesize() gibi platforma özgü bir sistem çağrısı kullanabilirsiniz.
Dikkat edilmesi gereken son bir uyarı da, desteklenen hizalama kümesinin C++ standardı tarafından değil, kullandığınız standart kütüphanenin uygulaması tarafından tanımlandığıdır.
Bölüm ikiye devam etmek için tıklayınız.
C++ High Performance - Second Edition Book
Kaynaklar